发行说明
此页面记录了最新的发行说明。
目录
- 开发中
- V5.5.0 2024 年 11 月 10 日
- V5.4.1 2024 年 6 月 11 日
- V5.4.0 2024 年 6 月 6 日
- V5.3.4 2024 年 1 月 18 日
- V5.3.3,2023 年 10 月 5 日
- V5.3.2,2023 年 7 月 11 日
- V5.3.1,2023 年 4 月 1 日
- V5.3.0,2022 年 12 月 22 日
- V5.2.0,2022 年 7 月 6 日
- V5.1.0,2022 年 3 月 1 日
- V5.0.1,2022 年 1 月 7 日
- V5.0.0,2021 年 11 月 30 日
- V4.1.3,2021 年 11 月 15 日
- V4.1.2,2021 年 11 月 14 日
- V4.1.1,2019 年 12 月 26 日
- V4.1.0,2019 年 7 月 7 日
- V4.0.0,2018 年 10 月 29 日
- V3.05.02,2018 年 6 月 19 日
- V3.05.01,2017 年 6 月 1 日
- V3.05.00,2017 年 2 月 16 日
- V3.04.01,2016 年 2 月 16 日
- V3.04.00,2015 年 7 月 11 日
- V3.03(rc1),2014 年 2 月 4 日
- V3.02.02,2012 年 10 月 23 日
- V3.01,2011 年 10 月 21 日
- V3.00,2010 年 9 月 30 日
- V2.04,2009 年 6 月 30 日
- V2.03,2008 年 4 月 22 日
- V2.02,2008 年 4 月 21 日
- V2.01,2007 年 8 月 30 日
- V2.00,2007 年 7 月 18 日
- V1.04,2007 年 5 月 15 日
- V1.03,2007 年 2 月 3 日
- V1.02,2006 年 10 月 4 日
- V1.01,2006 年 9 月 7 日
- V1.00,2006 年 6 月 17 日
开发中
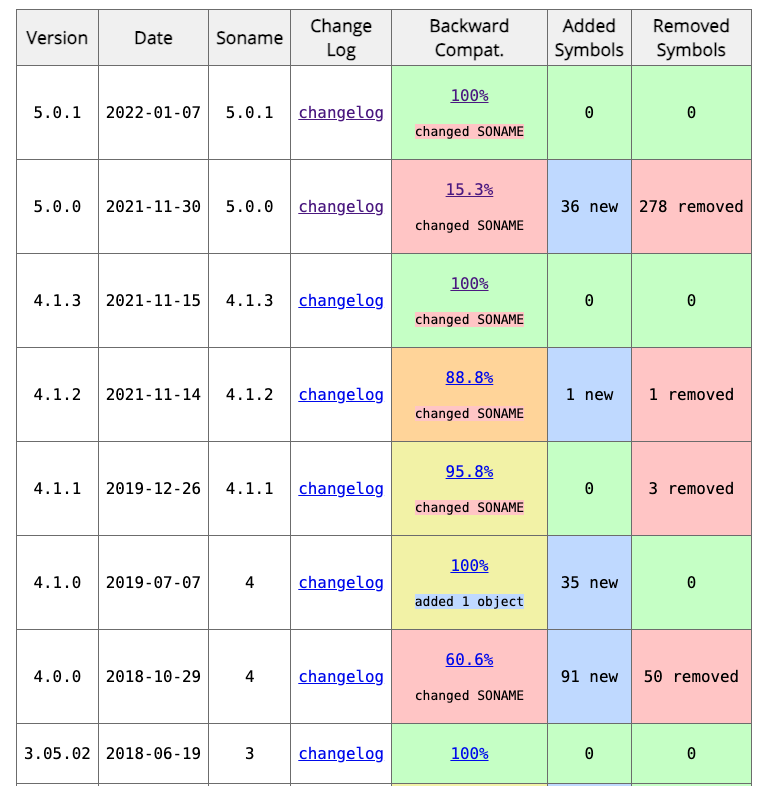
Tesseract 的 API/ABI 更改审查

V5.5.0
2024 年 11 月 10 日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.5.0
V5.4.1
2024 年 6 月 11 日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.4.1
V5.4.0
2024 年 6 月 6 日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.4.0
V5.3.4
2024 年 1 月 18 日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.3.4
V5.3.3
2023 年 10 月 5 日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.3.3
V5.3.2
2023 年 7 月 11 日
https://github.com/tesseract-ocr/tesseract/releases/tag/5.3.2
V5.3.1
2023 年 4 月 1 日
通过在 PR #4022 中稍微调整格式来改进 DebugDump 输出。作者:@GerHobbelt。
错误修复
- 修复 FP 除以零 (问题 #3995)。作者:@stweil 在 PR #3996 中。
- 修复问题 #3997 和 #4010。启用一些在编译时禁用传统引擎时错误禁用的代码块。作者:@amitdo 在 PR #4041 中。
- 通过包含
<cstdint>来修复使用 GCC 13 编译。作者:@kraj 在 PR #4009 中。
CMake 构建系统
- 修复 icu 和 pango 的链接。作者:@autoantwort 在 PR #4006 中。
- (MSVC 调试) 修复生成的
tesseract.pc文件中错误的 lib 名称。作者:@autoantwort 在 PR #4008 中。 - 修复生成的
tesseract.pc文件中的 libdir。作者:@ferdnyc 在 PR #4013 中。
编译器支持
我们不再支持 GCC 和 libstdc++ 8.x。
V5.3.0
2022 年 12 月 22 日
LSTM 训练:扩展函数 BoxFileName 以处理另一种图像名称扩展名 .raw.png。作者:@bertsky 在 PR #3962 中。
错误修复
- 修复传统 OCR 引擎的训练工具(问题 #3925)。作者:@stweil 在 PR 中:#3970,#3972,#3977。
- PDF 渲染器:忽略非文本块(修复问题 #3957)。作者:@amitdo 在 #3959 中。
- 在阈值处理之前移除颜色映射(修复问题 #3940)。作者:@zdenop。
- 修复 Coverity Scan 报告的几个性能问题。作者:@stweil 在 PR #3967 中。
- 训练工具:在
main函数中用 return 语句替换exit函数的调用。作者:@stweil 在 PR #3878 中。 - 修复函数
vigorous_noise_removal中的双重释放(问题 #3876)。作者:@stweil 在提交ee34b100bf中。 - 在
Textord::make_spline_rows中根据需要创建to_win(修复问题 #3875)。作者:@stweil 在提交99d6717c10中。 - 修复
ScrollView::MessageReceiver中的内存问题(问题 #3869)。作者:@p12tic 在 PR #3872 中。 - 在
SVNetwork::SVNetwork中捕获潜在的nullptr。作者:@stweil 在提交02e834000c中。 - 对函数
ObjectCache::DeleteUnusedObjects进行现代化改造(修复与 sanitizers 的问题)。作者:@stweil 在 PR #3978 中。
构建系统
- 将
svpaint.cpp从src/viewer移动到src/。在 Autotools 中添加 svpaint 可执行文件的规则。 - 修复 FreeBSD 上使用 Autotools 检测 AMD64。
- 修复从 CMake 生成的
tesseract.pc,使其与 Autotools 匹配。
V5.2.0
2022 年 7 月 6 日
- 添加对 Intel AVX512F 的初步支持。这提高了使用“最佳”模型进行识别以及训练的性能。
- C API:添加一个函数,使用来自内存的训练数据初始化 tesseract。
- 添加一个新的参数
invert_threshold。默认值为0.7。在之前的 5.x 版本中,反转阈值为0.5,用户无法更改该值。参数tessedit_do_invert已弃用,将在 6.0 版本中删除。要完全禁用文本行反转,可以将invert_threshold值设置为0.0。 - 修复 UZN 文件的回归问题。
- 用函数调用替换对 Leptonica 内部数据结构的直接访问(这对于与下一个 Leptonica 版本兼容是必需的)。
- 用
std::string函数替换std::regex(问题 #3830)。 - 修复 32 位主机上非常大的 PDF 文件。
- 在使用某些版本的 32 位 MSVC 编译器编译时,为 AVX2 代码设置
/Os(问题 #3769)。 - 在 Windows 上也使用编译后的
TESSDATA_PREFIX。 - C API:修复使用
malloc分配的内存调用delete[]。 - 改进 CI 构建定义。
- 改进 Autotools 和 CMake 构建定义。
V5.1.0
2022 年 3 月 1 日
- 在 ALTO、hOCR 和文本输出格式中处理图像和行分隔符区域。
- 其他一些增强功能。
- 一小部分错误修复。
- 删除未使用的代码。
- 将最低要求的 CMake 版本提升到 3.10。
V5.0.1
2022 年 1 月 7 日
- 修复使用 GCC 11 编译的 msys2 构建问题。
- 在运行 URL 上的 OCR 时,支持多达 8 个重定向。
- 在
STATS::pile_count()中捕获nullptr。 - 删除
NetworkIO::ZeroTimeStepGeneral()。这允许更多内联代码(优化)。 - 更新查找表的生成器,使用
TFloat而不是double。 - 修复
functions.h中的 clang 编译器警告。新代码避免了一些在double和float之间的转换,因此它对性能也应该有积极影响。 - 修复编译器警告 [
-Wsign-compare]。 - 修复由空语句引起的编译器警告。
- 修复一些其他编译器警告。
- 删除未使用的代码。
- 在公共包含文件添加
SPDX-License-Identifier。
CMake 构建
- 正确检测
amd64、x86_64、i386和i686目标。 - 如果 pkg-config 不存在,则不要尝试配置训练工具。
- 安装 tesseract 配置文件。
V5.0.0
2021 年 11 月 30 日
- 显著的性能改进
- 支持
float(32 位)进行 LSTM 模型训练和文本识别。现在float是默认值,而不是double(64 位)。这意味着更少的 RAM 消耗和更快的程序执行速度。 - 仅当平均置信度低于 50% 时,才尝试在反转行上进行 OCR (#3141)。
- SIMD
- 为 Arm Neon 添加手动点积支持。
- 还有许多其他改进。
- 支持
- 通用增强功能
- 添加两种新的基于 Leptonica 的二值化方法:自适应 Otsu 和 Sauvola。对于用户:使用
tesseract --print-parameters | grep thresholding_查看相关的可配置参数。 - 禁用五线谱检测和移除,因为它会干扰表格检测功能。将
pageseg_apply_music_mask的默认值更改为false。 - 添加一个新的命令行选项
--print-fonts-table。打印字体列表(id、名称)。仅适用于为传统 OCR 引擎提供数据的训练数据文件。 - 添加一个新的参数
tessedit_font_id。它可以用来强制 Tesseract 从训练数据文件使用特定字体来识别图像中的文本。 - 添加一个新的命令行选项
--loglevel。 - 添加一个新的选项
-l,用于combine_tessdata,以获取使用 LSTM 引擎训练的训练数据的网络规范。 lstmtraining工具:将--max_iterations的负值解释为 epochs。- 从 NFKC 切换到 NFC 规范化(或如果请求分解模式,则从 NFKD 切换到 NFD)。
- 文本输出:不要在单页图像中添加页面分隔符。
- hOCR 输出:将
scan_res属性写入ocr_page。 - 在之前的版本中,
pdf.ttf用于 PDF 渲染。在 5.0.0 中,这个文件不再需要。伪字体现在已嵌入代码中。
- 添加两种新的基于 Leptonica 的二值化方法:自适应 Otsu 和 Sauvola。对于用户:使用
- 代码现代化
- 从公共 API 中移除自定义数据类型
STRING、GenericVector和PointerVector。完全从代码库中移除的STRING类型被std::string替换。在代码库中,GenericVector类型主要被std::vector替换。PointerVector部分被std::vector替换。 - 使用
std::bitset<16>而不是自定义BITS16。 - 用现代 C++ 代码替换 malloc 和 free。
- 用
std::string替换strdup和free。 - 用
std::to_string替换一些snprintf。 - 用 C++ 类型转换替换 C 样式类型转换(修复
-Wold-style-cast编译器警告)。删除不必要的类型转换。 - 用 struct 替换 typedef struct。
- 使用
std::swap而不是自定义函数。 - 在更多地方使用
unique_ptr/make_unique。 - 使用 clang-tidy 对代码进行现代化改造。
- 对代码库进行了许多其他更改,使其现代化。
- 从公共 API 中移除自定义数据类型
- 训练脚本
- 删除基于 Bash 的训练脚本。如果你仍然需要这些脚本,你可以在存储库 history 中找到它们。请不要打开新的问题询问这些过时不支持的脚本。
- 将基于 Python 的训练脚本移动到 tesstrain 存储库。
- 构建系统
- 重构 Autotools 构建。它现在使用非递归 (auto)make。
- configure.ac:将最低要求的 autoconf 版本更新为 2.69。
- 将最低要求的 Pango 版本提升到 1.38.0。
- libtesseract API
- 此版本包含对公共 API 的重大更改。版本 5.0.0 与 4.x 不兼容。使用 libtesseract 的开发者需要调整他们的代码以适应这些更改。
- 减少公共头文件的数量。这包括
genericvector.h和strng.h头文件。 - 从 API 中删除一些不必要的函数。
- 源代码布局重组、文件重命名
- 所有公共头文件现在都放在
include/tesseract目录中。 - 将
tess_version.h.in重命名为version.h.in。 - 将
platform.h重命名为export.h。 - 将
src/api/tesseractmain.cpp移动到src/tesseract.cpp。 src/training目录:将训练工具与库分离。
- 所有公共头文件现在都放在
- 更新的要求
- 要从源代码构建 Tesseract,需要具有良好 C++17 支持的编译器。
V4.1.3
2021 年 11 月 15 日
修复损坏的 autotools 构建。
V4.1.2
2021 年 11 月 14 日
- 将
RowAttributes()从LTRResultIterator移动到PageIterator。 - 将用于训练的图像最大允许宽度从
2560更改为4096。 - 添加
SVMutex和SVSemaphore析构函数以避免系统对象泄漏。 - 不要输出空的 ALTO
sourceImageInformation。 - 扩展 Tesseract 与 libcurl 的 URI 支持。
- 警告并停止使用整数模型完成的 LSTM 训练过程。
Autotools 构建中的更改
- 修复 MacOS 的 autoconf 构建。
- 修复由于重新定义
DEFAULT_INCLUDES引起的 automake 警告。 - 不要在 autoconf 构建中使用编译器标志
-march=native -mtune=native。 - 默认情况下,使 automake 构建的噪音更小。
V4.1.1
2019 年 12 月 26 日
- 添加对通过 URL 获取图片或图片列表的支持。此功能使用 libcurl 实现。用法:
tesseract http://IMAGE_URL OUTPUT ... - 添加参数
document_title用于在 OCR 输出文件 (hOCR、PDF、ALTO) 中设置标题。 - 添加参数
tessedit_do_invert,当设置为false时可以加速 tesseract 执行。 - 添加参数
pageseg_apply_music_mask以允许禁用音乐遮罩。 - 在 ALTO 渲染器中添加 ComposedBlock 层级,使其更符合 hOCR 渲染器。
- 训练。扩展函数
BoxFileName以处理更多图像名称:.bin.png和.nrm.png。在 PR #2686 中。 - 修复自 4.1.0 版本以来发现的更多区域设置处理问题。
- 修复 text2image 中的内存泄漏。
- 修复通过运行 UndefinedBehaviorSanitizer 发现的潜在错误。
- 修复 Coverity Scan 报告的许多问题。
- 代码清理和现代化。
- 代码优化。
- 许多错误修复。
- 添加使用 sw 构建系统和包管理器构建 tesseract 的选项。使用 cppan 构建已弃用。
V4.1.0
2019 年 7 月 7 日
- 与 4.0.0 向后兼容版本
- 添加一个选项,使用可配置变量
dotproduct选择点积函数。可能的值:auto(默认)、generic、native、avx、sse。 - 添加一个新的输出选项,格式化为 ALTO 标准。命令行用法:
tesseract imagename outputbase alto。此输出为实验性,在下次发布之前可能会进行一些更改。 - 添加新的渲染器 LSTMBox、WordStrBox 以简化训练。
- 在 hOCR 输出中添加字符框。
- 添加 Python 训练脚本(实验性)作为 shell 脚本的替代方案。
- 修复区域设置处理问题。libtesseract 现在可以使用任何区域设置。
- 更好地支持 AVX / AVX2 / SSE。
- 修复边界框问题。
- 在 LSTM 引擎中实现了对白名单/黑名单的支持。
- 使用户单词和用户模式文件适用于 LSTM 引擎。 #2328
- 代码现代化和改进。
- 大量错误修复。
- 改进 CMake 配置。
- 默认情况下禁用 OpenMP 支持。这在 CMake 构建中完成,但在 Autotools 构建中没有完成,OpenMP 在 Autotools 构建中仍然默认启用(例如,请参见 #1171、#1081)。
V4.0.0
2018 年 10 月 29 日
- 新的 OCR 引擎
- 添加了一个新的 OCR 引擎,该引擎使用基于 LSTM 的神经网络系统,精度大幅提升。
- 这包括用于 LSTM OCR 引擎的新训练工具。可以从头开始训练新模型,也可以通过微调现有模型来训练新模型。
- 将包含 LSTM 模型的训练数据添加到 123 种语言 中。
- 为 LSTM 识别器添加了可选的加速代码路径。
- 使用 OpenMP
- 使用 SIMD:AVX2 / AVX / SSE4.1
- 添加了一个新参数
lstm_choice_mode,允许在 hOCR 输出中包含备选符号选项。
- 其他 OCR 引擎
- 在先前版本中作为主要 OCR 引擎的模式匹配 OCR 引擎在本版本中仍然可用。
- 从代码库中删除了 'Cube' OCR 引擎。它用于印地语和阿拉伯语。新的 LSTM 引擎性能要好得多,因此 Cube 引擎不再需要。
- 更新了构建系统
- Tesseract 现在使用 语义版本控制。
- 添加了一个选项,用于编译 Tesseract 而不使用旧版 OCR 引擎的代码。
- 更新的要求
- 要从源代码构建 Tesseract,需要使用具有良好 C++11 支持的编译器。
- Tesseract 现在需要 Leptonica 1.74.0 或更高版本。
- 将所需的最低 autoconf 版本更新为 2.63。
- 训练工具依赖项 - 将所需的最低版本更新为:ICU 52.1、Pango 1.22.0。
- 错误修复和增强功能
- 修复了许多会导致编译器警告的问题。
- 修复了 Coverity Scan 或 LGTM 报告的许多问题。
- 修复了训练数据渲染问题。
- 修复了处理 PDF 时对二进制图像的损坏。
- 不要在发布代码中为致命错误触发故意的分段错误 (Commit 5338a5a8d)。
- 修复了 OpenCL 代码中的一些问题。OpenCL 现在适用于旧版 Tesseract OCR 引擎,但不会提高性能。它没有为 LSTM OCR 引擎实现。
- 改进了多页 TIFF 处理。
- 改进了 PDF 渲染。
- 将版本信息和改进的帮助文本添加到训练工具中。
- 添加了更快的 log2() 版本。
- 在
tesseract手册页中记录了使用包含图像列表的输入文本文件的选项。 - 使 'osd' 成为请求 psm 0 时默认的训练数据(目前此功能仅在命令行界面中实现,而不是在 API 中)。
- 从 hocr、pdf 和 tsv 配置文件中删除了
tessedit_pageseg_mode 1。如果需要,用户应明确使用--psm 1(Commit ecfee53ba)。 - 现在按字母顺序排列可用的语言和脚本列表。
- 参数
unlv_tilde_crunching更改为false,因为true作为值会导致 Tesseract 4 中出现问题(#948、#1449)。 - 添加参数:
min_characters_to_try。
- 其他。
- 重新组织了 Tesseract 的源代码树。现在大多数源代码都位于
src目录下。 - 将单元测试添加到主仓库。单元测试需要 Git 子模块和训练代码。
- 删除了过时的代码。
- 重新组织了 Tesseract 的源代码树。现在大多数源代码都位于
- 重要提示
- 新的 LSTM 引擎仍然不支持旧版引擎中的所有功能(请参见 缺少的功能)。
- Tesseract 现在需要所谓的“C”区域设置。这在将 Tesseract 作为库从 Java 或 Python 等编程语言中使用时主要会有影响。区域设置代表几个取决于语言(或语言变体)或国家/地区的设置。其中一些设置决定了符号的分类(例如,“这个字符是空格字符吗?”)或数字打印的方式(例如,“3.141”或“3,141”)。当前的 Tesseract 代码隐式地期望一些固定的设置,否则它将失败。因此,如果代码无法确定设置是否有效,它将在开始时使用断言失败。这对于默认情况下获得具有正确设置的“C”区域设置的 C 或 C++ 程序来说不是问题。所有其他用例目前必须确保在运行 Tesseract 代码之前切换到“C”区域设置。 已修复 版本 4.1.0 中。
V3.05.02
2018 年 6 月 19 日
此版本修复了一些错误,从 4.0.0 版本移植回来。
V3.05.01
2017 年 6 月 1 日
- 添加了一个选项,用于仅渲染 PDF 输出中的不可见文本层(不包含完整的输入图像)。
- 对 GenericVector 进行了一些优化。
- 修复了 –disable-graphics 构建。
- 修复了 –enable-visibility 构建(包括训练工具)。
- 修复了使用 '\r\n' 作为换行符读取配置文件的问题。
- OpenCL - 修复了一些问题。删除了大部分代码。
- 删除了无用代码。
V3.05.00
2017 年 2 月 16 日
- Tesseract 现在需要 Leptonica 1.74.0 或更高版本。
- 对 hOCR 输出进行了一些微调。
- 添加 TSV 作为另一种可选的输出格式。
- 修复了在 3.04.00 中使用 AnalyseLayout() 方法引入的 ABI 问题。
- text2image 工具 - 启用字体中可用的所有 OpenType 连字。此功能需要 Pango 1.38 或更高版本。
- 训练工具 - 将断言替换为 tprintf() 和 exit(1)。
- 修复了 Cygwin 兼容性问题。
- 改进了多页 TIFF 处理。
- 改进了嵌入式 PDF 字体 (pdf.ttf)。
- 启用从命令行选择 OCR 引擎模式。
- 将 tesseract 命令行参数 '-psm' 更改为 '–psm'。
- 为方向和脚本检测添加了新的 C API,删除了旧的 API。
- 将最低 autoconf 版本提升至 2.59。
- 删除了无用代码。
- 修复了许多编译器警告。
- 修复了内存和资源泄漏。
- 修复了 'Cube' OCR 引擎中的一些问题。
- 修复了 OpenCL 中的一些问题。
- 添加了使用 CMake 构建系统构建 Tesseract 的选项。
- 实现了 CPPAN 支持,便于 Windows 构建。
V3.04.01
2016 年 2 月 16 日
- 为 psm 0 添加了 OSD 渲染器。适用于单页和多页图像。
- 改进了 tesstrain.sh 脚本。
- 简化了 ScrollView 的构建和运行。
- 改进了 OS X Preview 实用程序的 PDF 输出。
- 对 hOCR 行高信息进行了不兼容修复 - 提交 134ebc3。
- 添加了在没有 Cube OCR 引擎的情况下构建 Tesseract 的选项 (-DNO_CUBE_BUILD)。
- 该项目使用 Travis CI 和 AppVeyor 持续集成服务。
V3.04.00
2015 年 7 月 11 日
- Tesseract 的开发现在使用 Git 完成,并托管在 github.com 上(以前我们使用 Subversion 作为 VCS,并将代码托管在 code.google.com 上)。
- Tesseract 现在需要 Leptonica 1.71 或更高版本。
- 删除了对 VS2008 的官方支持。
- 对训练系统进行了重大更新,这是对 100 种语言进行大量测试的结果。
- 超过 100 种语言 的新训练数据。添加了对 39 种额外脚本/语言的支持:amh、asm、aze_cyrl、bod、bos、ceb、cym、dzo、fas、gle、guj、hat、iku、jav、kat、kat_old、kaz、khm、kir、kur、lao、lat、mar、mya、nep、ori、pan、pus、san、sin、srp_latn、syr、tgk、tir、uig、urd、uzb、uzb_cyrl、yid。
- 添加了一个备用自适应分类器,当主分类器在大型文档上填满时接管。
- 使用 PIC 编译选项提高了性能。
- 对 PDF 输出中的不可见字体系统进行了重大更改,以提高正确性和与外部程序(特别是 ghostscript)的兼容性。
- 改进了字体识别。
- 对重度带音符号语言(泰语、越南语、卡纳达语、泰卢固语等)的版式分析进行了重大更改,以提高版式分析。
- 修复了基线偏移问题,因此识别可以从版式分析错误中恢复。
- 对代码进行了重大重构,以提高对困难图像的处理速度,尤其是在运行堆检查器时。
- 将参数从页面布局中的全局变量移动到 tesseractclass 中。
- 改进了单列版式分析。
- 允许使用 tesseract 命令行可执行文件将 OCR 输出到多种格式。
- 修复了混合 eng+ara 脚本的问题。
- 改进了数字中的脚本一致性。
- 对 control.cpp 进行了重大重构以启用行识别。
- 添加了 tesstrain.sh - 一个主要的训练脚本。
- 添加了 text2image 训练工具的功能,该功能仅列出可用的字体。
- 添加了 text2image 的功能,该功能可以对单词进行下划线。
- 提高了 PDF 输出图像处理的效率。
- 为使用 'print-parameters' 命令行选项列出的每个参数添加了参数描述。
- 将字体信息添加到 hOCR 输出中。
- 启用了多页文档的流式输入和输出。
- 许多错误修复。
V3.03(rc1)
2014 年 2 月 4 日
- Tesseract 现在需要 Leptonica 1.70 或更高版本。
- 添加了 OpenCL 支持(实验性)。
- 添加了新的训练工具 text2image,用于从文本和 TrueType 字体生成框/tif 文件对。
- 添加了对包含可搜索文本的 PDF 输出的支持。
- 删除了整个 IMAGE 类和 image 目录中的所有代码。
- Tesseract 可执行文件:支持输出到标准输出;有限支持从标准输入获取单页图像(尤其是在 Windows 上)。
- 将 Renderer 添加到 API,以允许文档级处理和文档格式的输出,例如 hOCR、PDF。
- 对单词级识别、波束搜索进行了重大重构,消除了无用代码。
- 对分类器进行了重构,使其更容易添加新的分类器。
- 通用化了特征提取器,以允许从灰度图像提取特征。
- 改进了上标/下标处理。
- 改进了基线拟合。
- 将 set_unicharset_properties 添加到训练工具中。
- 许多错误修复。
- 包含了更多训练源数据。
V3.02.02
2012 年 10 月 23 日
- Tesseract 现在需要 Leptonica 1.69 或更高版本。
- 将 ResultIterator/PageIterator 移动到 ccmain 中。
- 在输出迭代器中为希伯来语/阿拉伯语添加了从右到左/双向功能。
- 在版式分析/OCR 后处理中添加了段落检测。
- 修复了训练期间 x 高度不一致和过度裁剪的问题。
- 添加了同时多语言功能。
- 对顶层单词识别模块进行了重构。
- 添加了实验性方程式检测器。
- 改进了对输入图像分辨率的处理。
- 添加了用于错误分析的 Blamer 模块。
- 通过从 baseapi.h 中删除包含内容来清理外部使用的命名空间。
- 删除了无用的内存管理代码。
- 整理了对控制参数的约束。
- 在分类器和训练中添加了对 ShapeTable 的支持。
- 对类修剪器进行了重构。
- 修复了训练泄漏和随机性。
- 对版式分析进行了重大改进,以实现更好的图像检测、带音符号检测、更好的文本行查找、更好的制表符查找。
- 改进了行检测和删除。
- 为 CJK 添加了固定间距切片器。
- 将 UNICHARSET 添加到 WERD_CHOICE 中,以使多语言处理更轻松。
- 修复了内部缩放图像的问题。
- 将页面和边界框添加到 tr 文件中的字符串中,以更好地识别训练数据的来源。
- 修复了印地语 Shiroreka 分割器的问题。
- 添加了单词二元语法校正。
- 减少了堆栈内存消耗,并消除了某些难看的类型定义。
- 添加了新的统一分类器 API。
- 添加了新的训练错误计数器。
- 修复了 dawg 阅读器中的字节序错误。
- C API(感谢 Tobias Müller)
- VS 2008 的新解决方案(感谢 Tom Powers)
- 修复了切片器查找切片并在此过程中弄乱轮廓的方式。
- 许多其他修复。
V3.01
2011 年 10 月 21 日
- 线程安全!将所有关键的全局变量和静态变量移动到相应类的成员中。Tesseract 现在是线程安全的(多个实例可以在多个线程中并行使用),但有一个小例外,即某些控制参数仍然是全局的,会影响所有线程。
- 添加了
Cube,这是一个新的实验性识别器,用于阿拉伯语和印地语。Cube 还可以与普通 Tesseract 结合使用,用于其他一些语言,精度略有提高,但速度会降低很多。Cube 没有训练模块。 OcrEngineMode在Init中替换AccuracyVSpeed以控制 Cube。- 极大地改进了分割搜索,从而提高了精度和速度,尤其是对汉语而言。
- 添加了
PageIterator和ResultIterator作为从 Tesseract 获取完整结果的更简洁方法,而这些方法目前没有在任何TessBaseAPI::Get*方法中提供。所有其他方法,尤其是ETEXT_STRUCT,都已弃用,将在将来删除。 - ApplyBoxes 已经完全重写,使训练更容易。现在它可以处理接触/重叠的训练字符,新的 boxfile 格式允许使用单词框而不是字符框,但是要使用此功能,您必须已经使用字符框对语言进行了引导。 “对 traineddata 的循环依赖。”
- 在页面布局分析中添加了自动方向和脚本检测。
- 删除了 **大量** 无用代码。
- 用可扩展的数据驱动模块替换了 Fixxht 模块。
- 输出字体特征准确性提高。
- 删除了每次分类时的双重转换。
- 将最旧的结构升级为类,并弃用 PBLOB。
- 删除了非确定性基线拟合。
- 为中文添加了固定长度的 dawgs。
- 垂直文本处理改进。
- 领导点的处理改进。
- 表格检测大幅改进。
- 修复了几个内存泄漏。
- 修复了输出文本中的字体标签。(并不完美,但比以前好很多。)
- 清理和更多错误修复
- 针对 Hindi 的特殊处理。
- 支持在 VS2010 中构建,使用 Microsoft Windows SDK for Windows 7(感谢 Michael Lutz)
V3.00
2010 年 9 月 30 日
- 线程安全的准备工作
- 将 TessBaseAPI 方法更改为非静态方法
- 创建了用于存放实例数据的目录的类层次结构,并开始将代码移入这些类。
- 将阈值代码移到一个单独的类中。
- 添加了主要的新的页面布局分析模块。
- 添加了 hOCR 输出。
- 添加了 Leptonica 作为主要图像 I/O 和处理。目前可选,但在将来的版本中,与 Leptonica 的链接将是强制性的。
- 重写了歧义表,以允许在 fix_quotes 的位置进行明确的替换。
- 添加了 TessdataManager 将数据文件合并到一个文件中。
- 删除了一些无用代码。
- 不再支持 VC++6。它无法处理模板的使用。
- 添加了更多语言。
- 大多数函数头注释的 Doxygen 化。
V2.04
2009 年 6 月 30 日
- 集成了可移植性补丁,以删除一些“访问”宏。
- 从查看器中删除了对 lua 的依赖,使其速度快了 **很多** 。此外,查看器现在可以编译并在(Linux 上)工作。也可以通过预构建的 ScrollView.jar 在 windows 上运行。
- 修复了以下问题:1、63、67、71、76、79、81、82、84、106、108、111、112、128、129、130、133、135、142、143、145、146、147、153、154、160、165、169、170、175、177、187、192、195、199、201、205、209。
- 这是支持 VC++6 的最后一个版本!
- 这也有可能是最后一个可以在没有 Leptonica 的情况下编译的版本!
- Windows 版本现在默认输出到 stderr,修复了缺少可见的、有意义的错误消息的许多问题。
V2.03
2008 年 4 月 22 日
2.02 由于最后一分钟的“简单”更改而无法运行。2.03 修复了这个问题。它还添加了对 leptonica 的包含检查,使其更易于使用。
V2.02
2008 年 4 月 21 日
- 对聚类、训练和分类器进行了改进。
- 针对大型字符集语言(例如 Kannada)的重大国际化改进。
- 删除了一些编译器警告。
- 添加了多页 tiff 支持,用于训练和运行。
- 更新了图形输出以与新的基于 java 的查看器通信。
- 添加了保存 n-best 列表的功能。
- 添加了 Leptonica 支持,用于更多文件类型。
- 改进了 Init/End 以使其安全。
- 减少了字典的内存使用。
- 在 TessBaseAPI 中添加了一些新 API。
- 修复了与 jpeg 库的命名空间冲突 (INT32)。
- 针对新代码的 Windows 可移植性修复。
- 针对新代码的 autoconf 系统更新。
V2.01
2007 年 8 月 30 日
(有关使用信息,另请参阅下面的 2.00 版本说明)
没有重大功能变化。只是进行了一些错误修复。
- 修复了 box 文件读取器中的 UTF8 输入问题。
- 修复了 dawg 代码中的各种无限循环和崩溃。
- 从 host.h 中删除了对 config_auto.h 的包含。
- 在 unicharset_extractor 中添加了自动 wctype 编码。
- 修复了 dawg 表过满的错误。
- 从 tarball 中删除了 svn 文件。
- 在 tessdll 中添加了新函数。
- 将分类结果中的最大 utf8 字符串增加到 8。
- 在 TessBaseAPI 中添加了用于 Ocropus 的新功能。
原始 6 种语言没有新的数据文件。使用 v2.00 中的文件。德语哥特体 (deu-f) 和巴西葡萄牙语 (por) 有新的数据文件。
**最新消息** unicharset_extractor 中存在一个小错误。由于这仅适用于训练,因此除非您需要运行训练,否则主 tarball 很好,在这种情况下,请用 tesseract-2.01.patch1.tar.gz 中的文件覆盖您的 unicharset_extractor.cpp 和 unicharset_extractor.exe。
V2.00
2007 年 7 月 18 日
(有关其他使用信息,另请参阅下面的 1.04 版本说明)
国际版的第一个版本。此版本识别以下语言
- 英语 - eng
- 法语 - fra
- 意大利语 - ita
- 德语 - deu
- 西班牙语 - spa
- 荷兰语 - nld
语言代码遵循 ISO 639-2。默认语言为英语。要识别其他语言
tesseract inputimage outputbase -l langcode
要在新语言上进行训练,请参阅 TrainingTesseract2。随着时间的推移,将出现更多语言。
此版本中的更改列表
- 将内部字符处理转换为 UTF8。
- 使用 6 种语言进行训练。
- 添加了 unicharset_extractor、wordlist2dawg。
- 添加了 boxfile 创建模式。
- 添加了 UNLV 回归测试功能。
- 修复了版权和注册符号问题。
- 修复了 extern “C” 声明问题。
- 对跨平台准确性的一致性进行了一些改进。
- 添加了 VC++ express 支持。
**警告:** Tesseract 2.00 比以前的任何版本都进行了更多兼容性测试。甚至还有一些修复,使跨平台的准确性更加一致。话虽如此,代码中也进行了许多更改,并且可移植性可能已被破坏,因此 64 位和 Mac 平台可能无法工作,甚至无法像以前一样构建。
V1.04
2007 年 5 月 15 日
Tesseract 开发现在使用 Subversion 完成,并托管在 code.google.com 上(以前我们使用 CVS 作为 VCS,并使用 sourceforge.net 进行托管)。
仅限 Windows 用户
为 windows 添加了一个 dll 接口。感谢 Jetsoft 的 Glen 为此做出的贡献。要使用 dll,请包含 tessdll.h,导入 tessdll.lib 并将 tessdll.dll 放在系统可以找到它的位置。还有一个小的 dlltest 程序来测试 dll。使用以下命令运行
dlltest phototest.tif phototest.txt
它将输出 phototest.tif 中的文本,并带有边界框信息。
Windows 的新功能
该发行版现在包含 tesseract.exe 和 tessdll.dll,它们 **可能** 可以开箱即用!没有保证,因为您需要 VC++6 版本的 MFC 和 CRT(至少)才能使其工作。(不包括电池,当然也不包括 installshield。)
对于使用 make 构建的任何人的重要说明:即除 devstudio 用户以外的任何人
此版本包含数据目录的新标准化。要使 Tesseract 能够找到其数据文件,您必须:
./configure
make
make install
将数据文件移动到标准位置,或者
export TESSDATA_PREFIX="directory in which your tessdata resides/"
(或等效项)在您的 .profile 或其他任何地方或 setenv 中设置环境变量。请注意,目录必须以 / 结尾
将 tesseract 和 tessdata **放在同一个目录中不再起作用**。
所有用户
修复了大量的名称冲突 - 主要与 STL 相关。进行了初步更改,以实现 unicode 兼容性。包括一个新的数据文件 (unicharset) 和其他数据文件的重命名,例如 eng,以支持不同的语言。此外,还修复了几个其他小错误,并为 64 位、最新的 Visual Studio 编译器等进行了 **可移植性改进** 。
感谢所有为这些修复做出贡献的人。
注意:这很可能是最后一个仅限英语的版本!对于非 Windows 用户,我们事先表示歉意,因为我们为发行版增加了 Windows 可执行文件。这可能会在下一个版本(具有多语言功能)中得到修复,因为这也会使发行版膨胀。
V1.03
2007 年 2 月 3 日
- 添加了 mftraining 和 cntraining。
- 添加了 baseapi,带有用于灰度和彩色的自适应阈值。
- 修复了许多内存泄漏。
- 修复了几个错误,包括缺乏自适应分类器的使用。
- 添加了 ifdefs 以消除图形代码并添加嵌入式平台支持。
- 合并了几个补丁,包括 64 位构建、Mac 构建。
- 准确性略有提高。
V1.02
2006 年 10 月 4 日
- 删除了对 Aspirin 的依赖。
- 修复了几个缺少的 Apache 许可证头文件。
- 删除了 $log。
V1.01
2006 年 9 月 7 日
- 为 VC++ 添加了 mfcpch.cpp 和 getopt.cpp。
- 修复了灰度图像和没有 libtiff 的问题。
- 阻止调试窗口用于使用输出。
- 修复了针对大端架构的 inttemp 加载。
- 修复了一些 Mac 编译问题。
V1.00
2006 年 6 月 17 日
Tesseract 的第一个 **开源** 版本!
托管在 sourceforge.net 上。CVS 用于版本控制。