提高输出质量
您可能无法从 Tesseract 获得高质量输出的原因有很多。需要注意的是,除非您使用非常不寻常的字体或新语言,否则重新训练 Tesseract 不会有任何帮助。
图像处理
Tesseract 在进行实际 OCR 之前,会在内部执行各种图像处理操作(使用 Leptonica 库)。通常它在这方面做得非常好,但不可避免地会有一些情况它无法做到最好,这会导致准确率大幅下降。
您可以通过使用配置变量 tessedit_write_images 设置为 true(或在运行 Tesseract 时使用配置文件 get.images)来查看 Tesseract 如何处理图像。如果生成的 tessinput.tif 文件看起来有问题,请尝试在将图像传递给 Tesseract 之前执行以下一些图像处理操作。
反转图像
虽然 tesseract 3.05(及更早版本)可以完美处理反转图像(深色背景和浅色文本),但对于 4.x 版本,请使用浅色背景上的深色文本。
重新缩放
Tesseract 在 DPI 为 300 dpi 或更高的图像上效果最佳,因此调整图像大小可能会有所帮助。有关更多信息,请参阅 常见问题解答。
“Willus Dotkom” 对 最佳图像分辨率 进行了有趣的测试,并提出了关于大写字母像素高度的最佳建议。
二值化

这将把图像转换为黑白。Tesseract 会在内部执行此操作(Otsu 算法),但结果可能不理想,尤其是在页面背景亮度不均匀的情况下。
Tesseract 5.0.0 添加了两种基于 Leptonica 的新二值化方法:自适应 Otsu 和 Sauvola。使用 tesseract --print-parameters | grep thresholding_ 来查看相关的可配置参数。
如果您无法通过提供更好的输入图像来解决此问题,可以尝试使用其他算法。请参阅 ImageJ 自动阈值(java)或 OpenCV 图像阈值(python)或 scikit-image 阈值 文档(python)。
噪声去除

噪声是图像中亮度或颜色的随机变化,它会使图像中的文本更难阅读。Tesseract 在二值化步骤中无法去除某些类型的噪声,这会导致准确率下降。
膨胀和腐蚀
粗体字符或细体字符(尤其是那些带有衬线的字符)可能会影响细节的识别,并降低识别准确率。许多图像处理程序允许膨胀和腐蚀字符边缘相对于公共背景,以膨胀或增大尺寸(膨胀)或缩小(腐蚀)。
历史文档中过重的墨迹渗透可以通过使用腐蚀技术来弥补。腐蚀可用于将字符缩小回其正常的字形结构。
例如,GIMP 的“值传播”过滤器可以通过降低“下阈值”来创建过粗历史字体的腐蚀效果。
原始
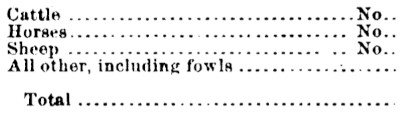
应用腐蚀
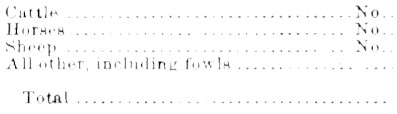
旋转/倾斜校正

倾斜的图像是指页面在扫描时没有保持直线。如果页面倾斜过度,Tesseract 的行分割质量会显著下降,从而严重影响 OCR 的质量。要解决此问题,请旋转页面图像,使文本行水平排列。
边框
缺少边框
如果您只 OCR 文本区域而没有任何边框,tesseract 可能无法处理它。有关一些详细信息,请参阅 tesseract 用户论坛#427。您可以使用 ImageMagick® 很容易添加一个小边框(例如 10 像素)。
convert 427-1.jpg -bordercolor White -border 10x10 427-1b.jpg
过大的边框
过大的边框(尤其是在处理单个字母/数字或大背景上的一个单词时)会导致问题(“空白页”)。请尝试将输入图像裁剪到文本区域,文本区域应具有合理的边框(例如 10 像素)。
扫描边框去除

扫描页面通常会在周围有深色边框。这些边框可能会被错误地识别为额外的字符,尤其是当它们形状和梯度不一致时。
透明度/Alpha 通道
某些图像格式(例如 png)可以有一个alpha 通道 来提供透明度功能。
Tesseract 3.0x 期望用户在将图像用于 tesseract 之前从图像中删除 alpha 通道。例如,可以使用 ImageMagick 命令完成此操作
convert input.png -alpha off output.png
Tesseract 4.00 使用 leptonica 函数 pixRemoveAlpha() 删除 alpha 通道:它通过与白色背景混合来删除 alpha 分量。在某些情况下(例如,电影字幕 的 OCR),这会导致问题,因此用户需要自己删除 alpha 通道(或通过反转图像颜色来预处理图像)。
工具/库
- Leptonica
- OpenCV
- ScanTailor Advanced
- ImageMagick
- unpaper
- ImageJ
- Gimp
- PRLib - 带有用于提高 OCR 质量的算法的预识别库
示例
如果您需要有关如何以编程方式提高图像质量的示例,请查看以下示例
- OpenCV - 旋转(倾斜校正) - c++ 示例
- Fred 的 ImageMagick TEXTCLEANER - 用于处理扫描的文本文档以清理文本背景的 bash 脚本。
- rotation_spacing.py - 用于自动检测文本图像的旋转和行间距的 python 脚本
- crop_morphology.py - 使用 Python、OpenCV 和 numpy 在图像中查找文本块
- 使用 OpenCV 和 Python 进行信用卡 OCR
- noteshrink - 关于如何清理扫描的 python 示例。博客中的详细信息 压缩和增强手写笔记。
- uproject text - 关于如何恢复图像透视的 python 示例。博客中的详细信息 使用椭圆形取消投影文本。
- page_dewarp - 使用“立方体纸张”模型对文本页面进行去扭曲的 python 示例。博客中的详细信息 页面去扭曲。
- 如何使用 OpenCV 从扫描图像中去除阴影
页面分割方法
默认情况下,Tesseract 在分割图像时会期望一个文本页面。如果您只想 OCR 一个小区域,请尝试使用不同的分割模式,使用 --psm 参数。请注意,为裁剪过紧的文本添加白色边框也可能有所帮助,请参阅 问题 398。
要查看支持的页面分割模式的完整列表,请使用 tesseract -h。以下是截至 3.21 的列表
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
字典、词表和模式
默认情况下,Tesseract 针对识别单词句子进行了优化。如果您尝试识别其他内容,例如收据、价格清单或代码,您可以采取一些措施来提高结果的准确性,并仔细检查是否选择了适当的分割方法。
禁用 Tesseract 使用的字典应提高识别率,因为大多数文本都不是字典词。可以通过将两个 配置变量 load_system_dawg 和 load_freq_dawg 设置为 false 来禁用它们。
也可以将单词添加到 Tesseract 使用的词表中以帮助识别,或添加常见的字符模式,如果您对预期的输入类型有一个很好的了解,这将有助于进一步提高准确性。这在Tesseract 手册中进行了更详细的说明。
如果您知道只会遇到语言中可用字符的子集,例如只有数字,则可以使用 tessedit_char_whitelist 配置变量。请参阅常见问题解答中的示例。
表格识别
众所周知,tesseract 在识别表格中的文本/数据方面存在问题(请参阅问题跟踪器),除非进行自定义分割/布局分析。您可以尝试使用/测试 Sintun 建议,或从 使用 PyTesseract 和 OpenCV 从表格图像中提取文本/提取表格图像文本的代码 中获得一些思路。
仍然有问题吗?
如果您尝试了上述所有方法,但仍然获得的准确性较低,请在论坛上寻求帮助,理想情况下,请发布示例图像。